안녕하세요, 약 6개월 만에 죽지도 않고 돌아온 블로그 주인장입니다..^,^ 지난 학기, 번듯한 개발 경험 한번 없이 얼레벌레 시작했던 졸업 프로젝트가 어느덧 막바지를 향해 달려가고 있네요.. 스타트를 끝낸 겨울 방학부터 그로쓰 종강이 한 달도 남지 않은 현재까지 많은 시행착오가 있었습니다.
시행착오 모음.zip
1. 모델 정확도를 높이고자 오랜 기간 동안 90,000개가 넘는 데이터와 싸우기
2. 그렇게 정리한 데이터로 6시간 동안 모델 학습하다 1시간 남기고 런타임 오류로 모델 저장에 실패하기
(모두들 Colab 사용하다 이런 경험.. 한 번쯤은 해보셨잖아요..?ㅎㅎ)
3. 기껏 데이터셋, 파라미터 조정해 가며 학습시킨 모델의 성능이 이전 모델보다 안 좋아서 폐기하기
4. 백엔드 서버 구축을 위해 인*런 Java Spring 강의 독학 하기
5. 그렇게 열심히 공부해서 서버 구축하고 초기 서비스 구현까지 마치고 백엔드 서버 없애기
6. 해결하고 나면 별일 아니었던 자잘한 오류들과 n시간 동안 끙끙대며 싸워 보기외의 2,938,120,381,236가지 시행착오들..^^
사실 프로젝트를 진행하다 보면 누구나 겪는 일상이지만,
이렇게 돌이켜보니 저 자신과 우리 팀원들 지난 1년간 참 고생 많았다고 말해주고 싶네요:D
우선 제가 진행 중인 프로젝트 주제는 [쉽고 편하게, 바른 글쓰기를 돕는 크롬 익스텐션 서비스]입니다. 저희는 각각 맞춤법 검사/격식체 문장 변환/단어 추천 기능을 제공하는 3개의 딥러닝 모델을 제작하였고, 모델 서버를 클라이언트와 연결하여 피드백 서비스를 제공하게끔 아키텍처를 설계하였습니다. 이쯤에서 각설하고 오늘은 모델 서버 구축 및 데이터 통신을 위한, FastAPI를 사용해서 RESTful-API를 만드는 방법에 대해 포스팅해 보겠습니다.
- 시작에 앞서, API란 무엇일까요?
API란 Application Programming Interface의 준말로, 쉽게 말해 '어떤 서버의 특정한 부분에 접속해서 그 안에 있는 데이터와 서비스를 이용할 수 있게 해주는 소프트웨어 도구'입니다. 그렇기에 API를 사용하면 서로 다른 두 개의 소프트웨어가 통신을 주고받을 수 있게 됩니다.
- 그렇다면 REST API는 또 무엇일까요?
REST API에서 REST란 Representational State Transfer의 준말로, 네트워크를 통해서 컴퓨터들끼리 통신할 수 있게 해주는 아키텍처 스타일입니다. REST API는 인터넷 식별자(URI)와 HTTP 프로토콜을 기반으로 작동하며, 데이터 포맷으로는 브라우저 간 호환성이 좋은 JSON을 사용하는 '단순함'이 핵심인 기술입니다. 대부분의 REST 방식의 API라면, 클라이언트-서버 모델로 구축되었다는 것을 의미하며, 전달하려는 데이터가 두 지점 사이를 왕복하게 됩니다.
Why FastAPI?
각기 다른 기능을 제공하는 3개의 딥러닝 모델에 대해 API를 작성하고 모델 서버를 구축하여 클라이언트와 데이터 통신을 하기 위해서 보다 단순하고, 직관적인 REST 방식의 API를 사용하기로 결정했습니다. Django나 Flask 등 API를 만들기 위한 다양한 파이썬 웹 프레임워크가 존재하지만 크게 복잡하지 않은 구조로 API를 작성할 수 있을 것 같다는 판단 하에, 실질적인 개발 시간 단축을 위해 초보자도 쉽고 빠르게 익힐 수 있다고 알려진 FastAPI를 사용해 개발을 진행하였습니다.
아래는 오늘 작성할 코드의 토대가 될 FastAPI 기본 코드 구성입니다.
#main.py
from fastapi import FastAPI
app = FastAPI()
@app.get("/")
async def root():
return {"message": "Hello World"}물론 FastAPI 개발을 위해 공부한 지식을 a-z 공유하면 더할 나위 없이 좋겠지만,,
블로그 글이 너무 쳐지고 길어질 것 같아 제가 작성한 코드 내에서 사용되는 부분만 우선 공유해보려고 합니다 :)
본문의 코드를 이해하고 따라오시기 위해서는 이 세 가지만 기억하시면 됩니다.
1. 서버 실행 코드 (두 코드 중 하나 선택)
// case 1
$ uvicorn main:app --reload
// case 2
$ uvicorn main:app --reload --host=0.0.0.0 --port=8000>> main : main.py의 main
>> app : main.py안에 있는 app=FastAPI()
>> --reload : 코드 변경 시 자동으로 저장되어 재시작됨
>> --host : 모든 접근이 가능하게 하려면 0.0.0.0을 입력한다 (선택사항)
>> --port : 접속 원하는 포트를 지정해 준다 (선택사항)
2. 대화형 API 문서(실행 결과 확인)
case 1: http://127.0.0.1:8000/docs
case 2: http://localhost:8000/docs

3. main.py 파일 코드 구조
app = FastAPI()
@app.get("/")
async def 함수 이름():
return {"데이터"}>> app : 앱 변수명(변경 가능)
>> app = FastAPI() : FastAPI 인스턴스 생성 (app 변수는 FastAPI 클래스의 "인스턴스")
>> / : 경로
>> get : 동작(operation)(변경 가능). HTTP 메서드 중 하나를 나타냄. 주로 POST, GET, PUT, DELETE 등이 쓰임.
>> @app.get() : 경로(end point) 동작 생성
>> async def : 비동기식 경로 동작 함수 정의
(FastAPI 공식문서에 사용법이 쉽고 자세하게 나와있으니 공식 문서를 참고해 가며 개발을 시작하시는 걸 추천드립니다!)
시작 전에,,
프로젝트 범위 내에서 전반적인 FastAPI 개발 과정의 이해를 돕기 위한 코드를 첨부한 것이고,
저희 서비스의 실행을 위한 완벽한 코드를 첨부한 것이 아닙니다. 이 점 유의해주세요!
0. FastAPI 설치
// pip 명령어를 통해 간단하게 설치 가능합니다. 아래의 코드로 설치할 경우 서버 역할을 하는 uvicorn도 자동으로 설치됩니다.
$pip install "fastapi[all]"1. main.py 파일 작성
// 3개 모델의 API를 모두 하나의 main.py 파일 안에 작성합니다.
1-1. 필요한 패키지 import 하기
from enum import Enum # 미리 정의 가능한 고정 변수 값
from typing import Union
from fastapi import FastAPI
from fastapi.responses import JSONResponse # json 형식으로 데이터 전달
import sys
import uvicorn1-2. local에 저장된 모델 불러오기 및 모델명 정의하기
# 모델 load
sys.path.append('/home/ubuntu/')
from KoSC import correction
from KoSST import paraphrasing
from WordRecTest import recommendWord
# 각각의 모델명을 선언할 Enum class 생성
class ModelName(str, Enum):
KoSST = "KoSST"
KoSC = "KoSC"
WordRec = "WordRec"1-3. FastAPI 인스턴스 생성
app = FastAPI()1-4. 엔드포인트 정의 : /models/{model_name}
// GET 동작을 사용하여 경로에 대한 요청을 받을 때마다 함수 호출합니다.
# 데이터 읽어오기
@app.get("/models/{model_name}")
async def runModel():
...1-5. 비동기식 함수 정의 및 매개변수 선언
// 선언 형식: (매개변수: 변수 타입)
// model_name: 열거형(ModelName) 타입, user_sentence: 문자열(str) 타입, MaskWord: 문자열(str) 또는 None
// model_name, user_sentence : 필수 for 문장 변환, 맞춤법 검사, 단어 추천
// MaskWord : 선택(Union) for 단어 추천
★// 필수로 필요한 매개변수는 각각에 해당하는 변수 타입으로 선언하고, 필수가 아닌 매개변수의 경우에는 Union[type] = None 꼴로 선언한다.
@app.get("/models/{model_name}")
async def runModel(model_name: ModelName, user_sentence: str, MaskWord: Union[str, None] = None):1-6. {model_name}의 값에 따라 다른 작업 수행
// KoSST와 KoSC는 문장을 입력받아 새로운 문장으로 출력하는 Transformer Model이고,
// WoedRec는 문장과 바꾸고 싶은 단어 하나를 입력 받아 roberta에 넣고 추천 단어 3개를 반환하는 Masked Language Model입니다.
1-6-1. {model_name} == "KoSST"인 경우
// 먼저, KoSST의 paraphrasing 함수는 다음과 같이 정의되어 있습니다.
# KoSST
def paraphrasing(text):
tokenized_text = tokenizer(text, return_tensors='pt', truncation=True)
with torch.no_grad():
outputs = model.generate(
tokenized_text['input_ids'],
do_sample = True,
eos_token_id = tokenizer.eos_token_id,
max_length = 512,
top_p = 0.7,
top_k = 20,
num_return_sequences = 1,
no_repeat_ngram_size = 2,
early_stopping= True
)
return tokenizer.decode(outputs[0], skip_special_tokens = True)
// 그렇기에 클라이언트에게 받은 문장을 모델에 넣어 paraphrasing 하여 다시 클라이언트에게 전달하는 API를 작성해야 합니다.
// user_sentence를 paraphrasing 함수로 처리한 결과를 new_sentence에 저장하고, model_name과 new_sentence을 담은 딕셔너리 sentence를 반환합니다.
// 참고: 딕셔너리(Dictionary)는 파이썬에서 제공하는 데이터 구조 중 하나로 고유한 키(Key)와 중복 가능한 값(Value)의 쌍으로 구성되며, 각 키는 해당하는 값을 가지고 있습니다.
@app.get("/models/{model_name}")
async def runModel(model_name: ModelName, user_sentence: str, MaskWord: Union[str, None] = None):
#case 1 : 격식체 전환 모델
if model_name.value == "KoSST":
new_sentence = paraphrasing("<s>"+user_sentence+"</s>")
sentence = {"model_name":model_name, "user_sentence" : new_sentence}
return sentence1-6-2. {model_name} == "KoSC"인 경우
// KoSC의 correction 함수는 KoSST의 paraphrasing 함수와 동일한 코드를 갖습니다. 따라서 위의 설명 및 코드에서 paraphrasing 대신 correction을 대입하여 이해하시면 됩니다.
@app.get("/models/{model_name}")
async def runModel(model_name: ModelName, user_sentence: str, MaskWord: Union[str, None] = None):
#case 2 : 맞춤법 검사 모델
if model_name.value == "KoSC":
new_sentence = correction("<s>"+user_sentence+"</s>")
sentence = {"model_name":model_name, "user_sentence" : new_sentence}
return sentence1-6-3. {model_name} == "WordRec"인 경우
// 먼저, WordRec의 recommendWord 함수는 다음과 같이 정의되어 있습니다.
// API 작성에 불필요한 코드들은 중간 부분 생략하였습니다.
#WordRec
#다음 사전에서 단어 입력하면 위에 뜨는 관련 단어들을 가져오는 함수
def search_daum_dic(query_keyword): #쿼리 키워드- 바꿀 단어
...
return word #word 배열 반환
#사용자가 바꾸려고 선택한(드래그한) 단어를 [MASK]로 치환해주는 함수
def masking(word_list, new_input, mask):
...
return new_sentence
#올바른 비교를 위해 모델의 input 문장과 유의어들을 전처리하는 함수
def preprocess(new_sentence, mask):
...
return new_sentence, synDict
#확률값을 계산하고 그 값이 큰 단어부터 텐서를 정렬하는 함수
def calculate(new_sentence):
...
return ts
#텐서 안에 32000개의 단어의 인덱스가 들어가있습니다. 그래서 그만큼 비교하는 루프를 작성했습니다.
def max_logit(tensor, synDict):
...
return word_list
def recommendWord(sentence,MaskWord):
origin = sentence
word_list = okt.pos(origin)
new_input=[] #단어만 넣을 배열 선언
for k in range(0, len(word_list)):
new_input.append(word_list[k][0])
hubo=word_list
#word_list 구조 : ('단어', '품사')
#word_list[0][1]: 0번째 단어의 품사
#word_list[1][0]: 1번째 단어의 단어
new_sentence = masking(word_list,new_input,MaskWord)
new_sentence, synDict = preprocess(new_sentence, MaskWord)
ts = calculate(new_sentence)
rec_word_list = []
# 1차원 배열 코드
rec_word_list = max_logit(ts, synDict)
result = [''] * len(rec_word_list)
for i in range(0,len(rec_word_list)):
result[i] = tokenizer.decode(int(rec_word_list[i]))
return result// 그렇기에 클라이언트에게 받은 문장과 단어를 모델에 넣어 recommendWord 하여 클라이언트에게 세 개의 단어를 전달하는 API를 작성해야 합니다.
// user_sentence와 MaskWord를 recommendWord 함수로 처리하여 추천 결과를 rec_word에 저장하고 추천 결과를 세 개씩 나누어 result1, result2, result3에 저장합니다.
// model_name, MaskWord, 추천 결과를 담은 딕셔너리 data를 JSONResponse로 반환합니다.
@app.get("/models/{model_name}")
async def runModel(model_name: ModelName, user_sentence: str, MaskWord: Union[str, None] = None):
#case 3 : 단어 추천 모델
if model_name.value == "WordRec":
rec_word = recommendWord(user_sentence, MaskWord)
result1, result2, result3 = [rec_word[i:i+3] for i in range(0, len(rec_word), 3)]
data = {
"model_name": model_name,
"masked_word": MaskWord,
"rec_result": [
{"result1": result1},
{"result2": result2},
{"result3": result3}
]
}
return JSONResponse(content=data)2. API 동작 확인
// 이제 main.py 파일 작성이 끝났습니다.
// FastAPI와 uvicorn 서버를 실행하면 docs 문서로 API의 동작을 확인할 수 있습니다.
// 저의 경우 팀원들과 함께 개발 중이기에 모든 호스트가 접근 가능하도록 아래의 코드로 실행했습니다.
$ uvicorn main:app --reload --host=0.0.0.0 --port=8000이후 http://localhost:8000/docs로 접속하셔서 문서 확인하시면 됩니다.


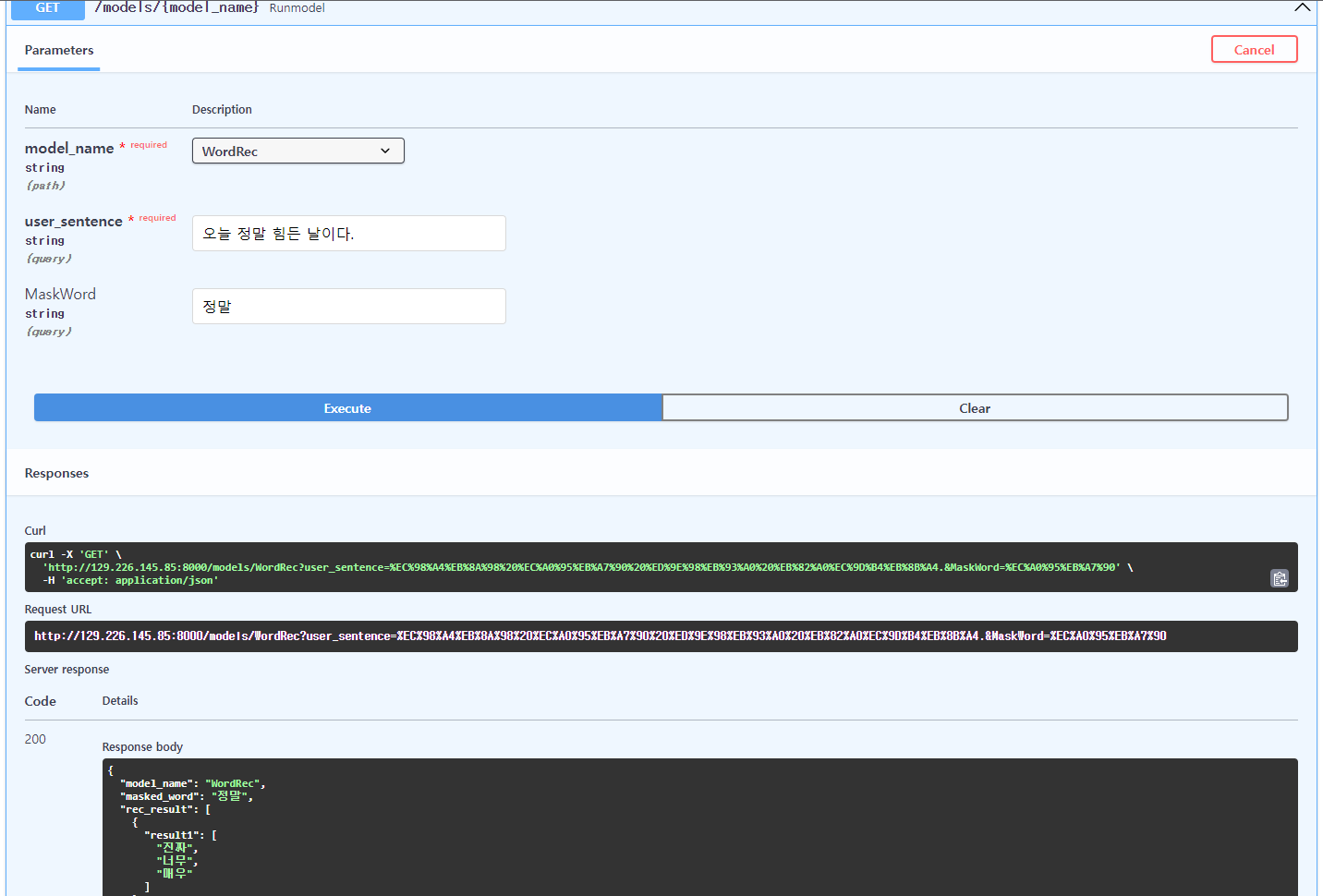
짠~ 이렇게 보시다시피 세 가지 경우 모두 잘 작동하는 것을 확인할 수 있습니다.
생각보다 간단하게 완성되지 않았나요?ㅎㅎ
저는 이번 기회에 FastAPI 처음 사용해 보았는데, 정말 편하고 좋은 프레임워크라는 생각이 들었습니다.
이제 HTTP 형식으로 Front-End(클라이언트)와 데이터를 주고받으면 됩니다. 이제 정말 끝이 보이나 싶었는데.. CORS 오류가 발생하였습니다. Chrome의 보안 문제 상 HTTP가 아닌 HTTPS(HTTP + SSL) 형식이어야 정상적으로 동작한다는 사실을 알게 되었습니다... ㅎ.ㅠ
일단 저희는 크롬 익스텐션 서비스라 도메인이 없는 상황이라
도메인 등록, ssl 발급, nginx 등등 이것저것 건드려가며 해결해 나갈 예정입니다. ^,ㅠ
아무튼! 졸업 프로젝트 잘 마무리하면 블로그에 홍보하러 오겠습니다. 긴 글 읽어주셔서 감사합니다.
'기술 블로그' 카테고리의 다른 글
| [deep learning] koBART를 사용한 비격식체-격식체 문장전환 (3) | 2022.11.25 |
|---|